Most of us are aware of tracing queries using SQL profiler. But an effective way of performing tracing is using a server side trace.
Whats special about server side trace?
1) Server Side trace uses much less resources than SQL Profiler.
2) Server side trace runs within the server which means the dependency on client tool is removed.In other words, when you run a profiler from a client machine, once you close the profiler, the SQL trace on the server stops. for ex: if the DBA is running a trace on production server from his desktop, then if the DBA's machine is restarted then the trace automatically stops. With a Server side trace as long as server is up the trace will be running and it doesnt depend on any client machine or tool.
3) SQL Profiler tool, while running, consumes lots of space on the C: drive ( or on the drive executables are installed ) by writing temporary files to C:\...\..\ temp folder. Temporoary files are cleared only by stopping the profiler, which would mean stopping the trace. There are enough articles on the net for Server Side traces. Please refer here and here. These links provide a fairly comprehensive expalantion on server side traces.
In short they say
1) configure the trace using profiler
2) Use the File and Export option on SQL Profiler to export the script of the trace.
3) Make the change on sp_trace_create parameter to 2 so that files roll over after the first trace file is filled up. If not the trace stops after the first trc file is full.
4) Execute it from SSMS to get the server side trace started.
5) Use the following functions to administer the trace
1) fn_trace_getinfo(default) or select * from sys.traces - to check trace status
2) sp_trace_setstatus - To start, stop and close a thread
3) fn_trace_gettable - To get the results of the trace files into a table.
Friday, December 24, 2010
Server Side trace
Wednesday, December 8, 2010
Perfmon counters list - Quest poster
Stumbled upon this PDF from quest which lists the important Perfmon counters and their acceptable values. A must print and stick poster which can be very very handy indeed. Saves so much of time and effort involved in reading pages of documents to know the important counters and correct value for each of them. Superb stuff. Thanks Quest !!!
Monday, November 29, 2010
Lock escalation : SQL Server 2008
Lock escalation is a event which occurs when SQL Server decides to upgrade a lock at a lower level hierarchy to a lock to a table level lock., In other words, when a particular query obtains a large number of row level locks/ page level locks, SQL Server decides that instead of creating and granting number of row level/page level locks, it is effective to grant a single table level lock. Or to be precise,
SQL Server upgrades the row/page level locks to table level locks. The above process is termed as lock escalation.
Lock escalation is good, as it reduces the overhead in maintaining a large number of smaller level locks. A lock structure is about occupies about 100 bytes of memory and too many locks can cause a memory pressure.Similarly applying,granting , and releasing locks for each row or page is a resource consuming processes which can be reduced by lock escalation. However, Lock escalation also reduces concurrency. ie, If a query causes lock escalation, then the query obtains a full table level lock, and another query attempting to access the table will have to wait till the first query releases the lock.
How SQL Server decides when to escalate lock ?
* When a query consumes more than 5000 locks per index / heap.
* When the lock monitor consumes more than 40% of the static memory or non AWE alloted memory.
So Let us quickly see lock escalation in action. Consider the following query
SET ROWCOUNT 4990
GO
BEGIN TRAN
UPDATE orders
SET order_description = order_description + ' '
--Rollback
The orders table has a clustered index. Row level locks will be taken on the index keys. SET ROWCOUNT ensures that only 4990 rows are updated by the query. I am leaving the transaction open ( without committing or rolling back ) , so that we can see the number of locks held by the query.
Fire the following query to check the locks held by the above script. The query lists the count of locks for each lock type and object. Note that the session id for the above script on my machine was 53. So filtering by the same.
SELECT spid,
COUNT(*),
request_mode,
[resource_associated_entity_id],
sys.dm_tran_locks.resource_type AS object_type,
Db_name(sysprocesses.dbid) AS dbname
FROM sys.dm_tran_locks,
sys.sysprocesses
OUTER APPLY Fn_get_sql(sql_handle)
WHERE spid = 53
AND sys.dm_tran_locks.request_session_id = 53
AND sys.dm_tran_locks.resource_type IN ( 'page', 'key', 'object' )
AND Db_name(sysprocesses.dbid) = 'dbadb'
GROUP BY spid,
[resource_associated_entity_id],
request_mode,
sys.dm_tran_locks.resource_type,
Db_name(sysprocesses.dbid) 
As one may notice, we can find 4990 key locks / row level locks. Let us rollback transaction and modify the script to use 5000 or more locks.
SET ROWCOUNT 5000
GO
BEGIN TRAN
UPDATE orders
SET order_description = order_description + ' '
--Rollback
Now let us fire the same query on sys.dm_tran_locks. we obtain a single exclusive lock on the table/object. There are no key or row level locks as SQL Server as per its rule has escalated the row level locks to a table level lock.
SQL Server 2005 had a server wide setting to disable lock escalations. On SQL Server 2005, when the trace flag 1211/1224 are set, no query is allowed to escalate locks on the entire server. Ideally, we would like to have it as a object/table level setting which was provided by SQL Server 2008. SQL Server 2008 allows one to disable lock escalations at table/ partition levels.
Consider the following command in SQL 2k8
ALTER TABLE orders SET CONSTRAINT (LOCK_ESCALATION = DISABLE )
GO
The ALTER TABLE command's LOCK_ESCALATION property accepts three values.
* Disable -> Disables lock escalation ( Except a few exceptions . Refer Books online for details )
* Table -> Allows SQL Server to escalate to table level. That is the default setting.
* Auto -> Escalation will be partition level if the table is partitioned. Else escalation is always up to table level.
Let us rollback the open transaction created earlier and run the ALTER TABLE command posted above to disable lock escalations. Now let us run the same script to update 5000 records again and see if lock escalation has actually occurred.
As you may now notice, for the same 5000 rows, there is no lock escalation occuring this time as we have disabled it using the ALTER TABLE command. The picture shows 5000 key/row locks which is not possible at the default setting of lock escalation.
The intention behind this post was to introduce lock escalation, show how it works and also explain the new option provided to change lock escalation setting SQL Server 2008. Upcoming posts, we will dive deeper into the topic and understand when and under what circumstances can we play with lock escalation setting.
Tuesday, November 16, 2010
Backup log Truncate_Only in SQL Server 2008
BACKUP LOG <db_name> WITH truncate_only command, used for clearing the log file, is deprecated in SQL Server 2008. So this post will explain option available in SQL Server 2008 for truncating the log.
Step 1: Change the recovery model to Simple
USE [master]
GO
ALTER DATABASE [dbadb]
SET recovery simple WITH no_wait
GO
Step 2: Issue a checkpoint
One can issue a checkpoint using the following command.
CHECKPOINT
GO
Checkpoint process writes all the dirty pages in the memory to disk. On a simple recovery mode, the checkpoint process clears the inactive portion of the transaction log.
Step 3: Shrink the log file
USE dbadb
GO
DBCC shrinkfile(2, 2, truncateonly)
Shrinking the log file with a truncateonly option clears the unused space at the end of the log file. First parameter of the Shrinkfile takes the filed id within the database. Mostly the fileid of the log file is 2. You may verify the same by firing a query on sysfiles.
Step 4: Change the recovery model back to full/bulk logged
Change the recovery model to the recovery model originally ( full/bulk logged ) used by the database.
USE [master]
GO
ALTER DATABASE [dbadb]
SET recovery FULL WITH no_wait
GO
After these steps the log file size should have reduced.
The intention behind this post is not to encourage truncating the log files. Use the method explained, only when you are running short of disk space because of a log file growth. Note that, Just like truncating log files, Changing the recovery model also disturbs the log chain. After clearing the log using the above method, you need to either run a full backup/Differential backup to keep your log chain intact for any recovery.
Just a quick demo to show that the log chain breaks if you change the recovery model.
The database whose log file we will be clearing is dbadb. Log file size 643 MB as shown below.
After executing the scripts mentioned above, the log file size is 2 MB as shown below.
The log chain breaks after changing the recovery model. When log chain breaks, subsequent transaction log backups start failing as shown below.
Transaction log backups will be successful only after the execution of full or differential backup.
PS: Pardon me for a SQL 2k8 post, when the whole world is going crazy about
SQL Denali :)
Tuesday, November 9, 2010
Finding CPU Pressure - dm_os_schedulers DMV
The last post dealt with checking CPU pressure using wait_stats DMV. But, to get a complete picture of CPU Pressure, the script provided in the previous post alone wouldn't suffice. We need the help of additional DMV
sys.dm_os_schedulers.
Why we need the help of sys.dm_os_schedulers?
As already mentioned, Waitstats DMV captures waiting time for a group of wait types. WaitStats DMV works in the following way. WaitStats checks whether any processes waits at any of the defined wait types. If yes, then WaitStats tracks resource wait time experienced by the process. After the resource wait is over, waitstats tracks the signal wait/CPU wait. Once, both the waits are completed, the waitstats reflect in the DMV.
There have been scenarios where a process doesn't experience any resource wait and just has a CPU wait/Signal wait. In such a case, the waiting time misses the wait stats, and wait stats doesn't reflect the CPU pressure experienced at all. In other words, if a process doesn't wait for any resource and directly gets
into the CPU queue and spends long time only in runnable state, then
sys.dm_os_wait_stats doesn't reflect it. The Same scenario is explained in detail by MVP Linchi Shea over here.
In such a scenario, one can use sys.dm_os_schedulers to detect CPU pressure.
Consider the following query.
SELECT scheduler_id,
cpu_id,
current_tasks_count,
runnable_tasks_count,
current_workers_count,
active_workers_count,
work_queue_count
FROM sys.dm_os_schedulers
WHERE scheduler_id < 255;
Simple and straight forward query on sys.dm_os_schedulers DMV. Returns one row per CPU. Scheduler_id < 255 filters out schedulers used by system processes. Detailed explanation on the DMV can be obtained from here. Most important column is runnable_tasks_count which indicates the number of tasks that are waiting
on the runnable queue. Once a process moves out of the runnable state into running state, the value of the column reduces by one. So, the DMV always indicates the current state of the server and the runnable queue.dm_os_schedulers doesnt hold historical data since last restart unlike waitstats dmv. So, this needs to
polled lot more frequently, perhaps every 5 minutes if necessary. Any non zero value noted on runnable_tasks_count is a indication of CPU pressure and requires close monitoring.
To sum it up, CPU monitoring for SQL Server would include three parts.
* Directly checking CPU using sys.os_ring_buffers dmv as explained here.
* Checking waitstats dmv as explained here
* checking sys.os_schedulers as explained in this post.
Sunday, October 31, 2010
Finding CPU Pressure using wait_stats DMV
CPU Pressure forms vital part in performance monitoring and sys.dm_os_wait_stats is a good place to check. Some background info before we look at the DMV.
Waiting time for a SQL Process is divided into two. They are Resource waits and signal waits( CPU waits ). When a process/query is submitted to SQL Server, SQL Server checks whether all resources required for the process are available.Resources would include things like IO, Network, Memory, Locks, Latch waits etc. For Ex: If a process is waiting for another process to release its lock, then it becomes a resource wait because of locks. If a process wants to write something to a disk but its has to wait for some other IO activity to complete then its a resource wait because of IO. So all these waiting time gets categorized as resource waits..
After a process grabs all the resources it requires, the process gets scheduled to run/executed by the Processor/ CPU. So, it enters the CPU queue. If there are already many processes executing, then it has to wait to get the CPU. The time spent waiting for the CPU is termed as signal waits.
sys.dm_os_wait_stats DMV provides the cumulative sum of the waiting time experienced by all processes at each wait type. dm_os_wait_stats DMV is a SQL Server 2005/2008 equivalent of DBCC SQLPERF(waitstats). A lot more accurate explanation about the DMV is provided here . dm_os_wait_stats maintains these stats since last restart of the server or since the last execution DBCC SQLPERF ('sys.dm_os_wait_stats', CLEAR);
sys.dm_os_wait_stats provides about 485 wait types/wait events and waiting time spent at each wait type. Two interesting columns of this DMV are
* wait_time_ms
* signal_wait_time_ms
Wait_time_ms gives the total time spent at each wait type ( Resource + cpu wait ). signal_wait_time_ms specifies the time spent on waiting for CPU. Resource waittime can be found by wait_time_ms - signal_wait_time_ms.
SELECT SUM(signal_wait_time_ms) * 100 / SUM(wait_time_ms) AS
cpu_pressure_percentage,
SUM(signal_wait_time_ms) AS cpu_wait,
SUM(wait_time_ms - signal_wait_time_ms) AS resource_wait,
SUM(wait_time_ms) AS total_wait_time
FROM sys.dm_os_wait_stats 
Consider the query above. cpu_pressure_percentage provides percentage of time spent waiting for CPU, by finding the ratio of signal_time and total wait time. Microsoft recommends this value to be less than 25% for a normal system. Value any higher would indicate a system suffering likely from a CPU stress.
Most common causes for CPU stress/high signal waits can be
* Poor and ineffective query plans / missing indexes / table scans
* Too many Plan Recompliations
* Slow CPU and requires a upgrade
As a production DBA, its a good idea to collect the resultset dm_os_wait_stats DMV once few hours or twice or thrice a day and perhaps analyze the results to notice any surge in wait time. This can be one proactive approach to detect potential major problems.
Saturday, October 23, 2010
Backup path
Sometimes after taking a backup, one can forget the path where the backup was taken.
The simple script below provides the list of backups taken on the server, backup type ( log - l, Full -D..),backup start date and time, lsn numbers and the path of the backup. Simple and handy.
SELECT database_name,
TYPE,
backup_start_date,
first_lsn,
last_lsn,
backupmediafamily.physical_device_name
FROM msdb.dbo.backupset,
msdb.dbo.backupmediafamily
WHERE backupset.media_set_id = backupmediafamily.media_set_id
ORDER BY backup_start_date DESC 
Tuesday, October 19, 2010
Currently executing query - wait status
Recently, I had a developer who came to my desk with a request.
' I started a execution of a script from a program. the program has been running for a long time. I don't know whether its executing or hanging. Can you check from database whether the script is running or hanging and if hanging at which statement it is hanging?. If possible please tell me why its hanging..'
Earlier in my blog, I posted the following script to check the currently running query.
SELECT spid,
TEXT AS [query],
Db_name(sysprocesses.dbid) AS dbname,
cpu,
memusage,
status,
loginame,
hostname,
lastwaittype,
last_batch,
cmd,
program_name
FROM sys.sysprocesses
OUTER APPLY Fn_get_sql(sql_handle)
WHERE spid > 50
ORDER BY cpu DESC
The above query would give the stored procedure's name or starting statements of the script/batch and not the exact statement within the stored procedure or batch that is currently executing. To find that one should use sys.dm_exec_requests
SELECT session_id,
request_id,
Db_name(database_id),
start_time,
status,
command,
Substring(txt.TEXT, ( statement_start_offset / 2 ) + 1,
( ( CASE statement_end_offset
WHEN -1 THEN Datalength(txt.TEXT)
ELSE statement_end_offset
END
- statement_start_offset ) / 2 ) + 1) AS statement_text,
wait_type,
wait_time,
blocking_session_id,
percent_complete,
cpu_time,
reads,
writes,
logical_reads,
row_count
FROM sys.dm_exec_requests
CROSS APPLY sys.Dm_exec_sql_text([sql_handle]) AS txt
WHERE session_id <> @@SPID
AND session_id > 50
The query above gives the currently executing statement within a batch. sys.dm_exec_requests provides the columns statement_start_offset ,statement_end_offset which specify the starting and ending positions of the currently executing query within a batch, in bytes. As 'text' column returned by dm_exec_sql_text is of nvarchar datatype, statement_start_offset/2 is required to get to the starting postion of the query. statement_end_offset returns -1 to indicate the end of the batch.So, statement_text column of the query answers the first part of the developer's request.
Now, for the next part , ie finding the status of the query ie.. running/hanging/sleeping etc
A user request can take the following major states.
> Sleeping : Query completed execution and has nothing to do. Connection
is still not closed.
> Running : Currently running/executing.
> Runnable: Can run but waiting for a processor. Implies waiting in
processor queue.
> Suspended: Waiting for some resource or event. Wait may be because of
locks, IO completion, Latch or Memory wait etc.
Sleeping requests are not shown in sys.dm_exec_requests. Runnable/Suspended state requests are the ones we need to watch out for. Runnable/Suspended states are not abnormal, as long as they dont stay at the same state for a long time.
Now for the third part..' Why it is hanging..'
The wait_type column on the resultset will return the reason why a request is waiting. To know the meaning of each wait type refer here
Popular few wait types are given below
ASYNC_IO_COMPLETION - Waiting for IO
CXPACKET - Wait beacuse of Parallelism.
LOGBUFFER - Waiting for the logbuffer to release some space in the memory.
LCK_M% - Waiting for lock to be released. Refer to Blocking_Session_id for finding the blocking process.
Other interesting columns returned by dm_exec_requests are wait_time returning time spent waiting in ms, percent_complete indicating progress of the query,
cpu_time,reads,writes,logical_reads and row_count. percent_complete mostly indicates the progress for select queries,backup process but not for DML operations.
So, a quick execution of the script and checking the wait state details can clearly
show the current progress/ status of the request.
Monday, September 27, 2010
SQL Server never stores the same column twice
Consider the following table.
CREATE TABLE dbo.tbl
(
col1_pky INT PRIMARY KEY,
col2_nc_index INT
)
CREATE INDEX nc_col2_col1
ON dbo.tbl(col2_nc_index, col1_pky)
I have created a table dbo.tbl with the column col1_pky as primary key.
A composite Non Clustered index is created on col2_nc_index,col1_pky columns.As by definition every non clustered index contains the clustered index key.
So going by definition, the non-clustered index should contain the following
* col2_nc_index,col1_pky - Index definition
* col1_pky - Clustered Index key
col1_pky is supposed to repeat twice as its a part of the nonclustered index and also clustered index key. But, SQL Server avoids the same by not storing the same
column twice.
/* Data Generation Script */
DECLARE @col1 INT,
@col2 INT
SET @col1 = 1
SET @col2 = 10000
WHILE @col1 < 10000
BEGIN
INSERT INTO tbl
SELECT @col1,
@col2
SET @col1 = @col1 + 1
SET @col2 = @col2 - 1
END
As usual let us use DBCC IND / PAGE to check the same.
To check the root page
DBCC ind ( 'dbadb', 'tbl', -1) 
Root page is found as 18684
Let us take a look at the contents of root page using DBCC PAGE
DBCC traceon(3604)
GO
DBCC page(dbadb, 1, 18684, 3)
GO 
Note that col1_pky appears only once and doesnt appear twice. To confirm the same let us check the contents of a leaf level page.
DBCC page(dbadb, 1, 19044, 3)
GO 
Again col1_pky is present only once. So, SQL Server always stores a column only once in a table.
Sunday, September 12, 2010
Avoiding Explicit Permission - Execute as clause
Providing direct access on tables for application user accounts is always a security concern. But, there are some scenarios which forces us to do the same. I previously discussed it in detail over here. SQL Server 2008/2005 provides a few options to avoid providing direct rights, even when the stored procedure involves dynamic sql, DDL, cross database reference etc. This post will explore one such option.
Execute AS option:
While creating stored procedures, we can specify EXECUTE AS clause to run the stored procedure under a different account. For example consider the following
CREATE PROCEDURE dbo.Rights_check
AS
BEGIN
DECLARE @txt NVARCHAR(100)
SET @txt = 'Select * from databaselog'
EXEC Sp_executesql @txt
END
GO
Let us grant rights to account test1, which doesn't have direct access to 'databaselog' table.
GRANT EXEC ON dbo.rights_check TO test1
GO
Executing the 'dbo.rights_check' procedure from 'test1' account fails as test1 doesn't have direct access on 'databaselog' table.Using 'Execute As' clause can allow test1 to execute 'dbo.rights_check' procedure successfully without directly providing rights on the 'databaselog' table.
ALTER PROCEDURE dbo.Rights_check
WITH EXECUTE AS owner
AS
BEGIN
DECLARE @txt NVARCHAR(100)
SET @txt = 'Select * from databaselog'
EXEC Sp_executesql @txt
END
I have just added the EXECUTE as OWNER clause on top which ensures that the stored procedure is executed in the context of owner of the stored procedure. Execution of the stored procedure using test1 is successful as expected.
The reason is, adding EXECUTE as OWNER allows any account which has execution rights on the stored procedure to execute under the security context of the owner of the stored procedure. This ensures that the executing account is allowed to obtain the special permissions only within the stored procedure and not outside the scope of it.
EXECUTE AS clause provides additional options like EXECUTE as 'user_name'. EXECUTE as 'user_name' allows one to execute under the context of particular user account instead of owner of the object.More details on the same can be read here.
EXECUTE AS clause effectively solves the security problems that arise when DDL statements, dynamic sql, cross database references are used.Digital Signatures, introduced in SQL Server 2005 also helps in addressing similar security problems which we will cover in the next post.
Monday, September 6, 2010
DBCC IND/ PAGE - Unique Non Clustered index structure
I am back after a short break. Few personal and official commitments have kept me away from posting. Apologies.From now on I will be posting at usual pace.
Continuing from my series of posts on DBCC IND, DBCC PAGE, this post will deal with the structure of Unique Non clustered index.Refer to the following links for previous posts on the same topic
1. DBCC IND/PAGE intro - Refer here
2. DBCC IND/ PAGE - Non Clustered Index structure on a table with Unique/Non unique Clustered index - Refer here
Structure of a Unique Non clustered index is different from ordinary ( Non unique ) non clustered index. The difference is that the Clustered index columns,
which are normally a part of Non clustered index, are not present in the Non leaf nodes when the Non clustered index is unique.When a Non clustered index is
unique, the clustered index columns are stored only in the leaves of the Non clustered index.
A detailed explanation on the same is given by the legendary Kalen Deanley :) Who else in the planet can explain internals better than her?
So, for more details on the topic, refer to her article here.
Tuesday, August 17, 2010
Stored Procedures , Explicit Permissions and Security concerns
Its always a good practice to have your code wrapped in stored procedures.
One of the reasons is Security. To explain a bit more, when one grants execution rights on a stored procedure to a user, the user gets the rights to perform all the operations ( Select/Insert/update/delete ) within the stored procedure.However, the same user cannot perform the operations outside the context of stored procedure.
Ex:
GRANT EXEC ON dbo.usp_stored_proc TO user1
Assume that the stored proc dbo.usp_stored_proc performs Select and update on table1, then user1 can perform these operations only while executing dbo.usp_stored_proc and not directly. In other words, user1 cannot bypass the stored procedure and directly perform a select/update on table1.
But there are a few operations, where one needs to explictly grant permission to a object inside a stored procedure.In other words, its not enough if we just grant EXEC rights on the stored procedure. Let me list down such scenarios.
1) Using Dynamic sql queries using sp_executesql / EXEC :
If your stored procedure is using Dynamic SQL using sp_executesql then the
objects accessed in the dynamic sql require explicit permissions.
For Example
CREATE PROCEDURE dbo.Usp_stored_proc
AS
BEGIN
DECLARE @dsql NVARCHAR(100)
SET @dsql = ' Select * from table1 '
EXEC Sp_executesql @dsql
END
GO
For the above stored procedure, its not enough if we grant execution rights to
dbo.usp_stored_proc. In addition,one needs to grant select rights on 'table1' for the user executing stored procedure. Explicit grant is required because dynamic sql are always treated as separate batch outside the scope of the stored procedure.
2) Cross database reference
If you are accessing a table on another database, then one needs to explicitly grant rights.
CREATE PROCEDURE dbo.Usp_stored_proc
AS
BEGIN
SELECT empid,
salary,
increment,
name
FROM hr_database.dbo.salary
WHERE username = 'clerk';
.......
...........
Some code
..........
...........
END
GO
In the above stored procedure, the salary from database 'HR_database' is accessed. The user who calls the stored procedure should have rights on the HR_database.dbo.salary for the stored procedure to execute successfully.
Please note that the above scenario is true, when cross database ownership chaining is not enabled.If cross database ownership chaining is enabled, and if both the objects(dbo.usp_stored_proc and HR_database.dbo.salary;) belong to the same owner, then explicit permissions need not be granted.
3) While using linked servers
CREATE PROCEDURE dbo.Usp_stored_proc
AS
BEGIN
SELECT *
FROM linkedserver.DATABASE.dbo.table2;
END
GO
On the above stored procedure, linked server is used to refer to a table in a remote server.In such a case, the login that maps the user ( executing the stored procedure ) to the remote server should have select rights on table2. For understanding login mappings on linked server refer here.
4) Using DDL statements
CREATE PROCEDURE dbo.Usp_stored_proc
AS
BEGIN
TRUNCATE TABLE dbo.t1;
END
GO
If the stored procedure contains DDL statement like truncate,alter table, Create index then appropriate rights should be granted to caller of the stored procedure.Meagre execution rights on the stored procedure wouldnt suffice.
On all the four scenarios listed above, ideally one would want the caller of the stored procedure to use these extra permissions only while executing the stored procedure. At the rest of the time, we wouldnt want the caller to gain direct access on the table.But by granting the rights explicitly, the caller of the stored procedure gets additional rights to perform the above mentioned operations without executing the stored procedure. ie, anyone can use the calling account and connect to the database and perform a Select on a entire salary table on HR_database or truncate a table t1, without executing stored procedure. Obviously, this can be a serious security concern.
To prevent the same, there are a few excellent options in SQL Server 2005, SQL Server 2008 which will be discussed in the next post.
Monday, August 9, 2010
DBCC IND/ PAGE - Non Clustered Index structure on a table with Unique/Non unique Clustered index
Continuing from the last post, let us analyze the structure of a non clustered index using DBCC IND/PAGE commands, when we have a clustered index on the table. To be specific, we will see the difference in structure of a Non Clustered index when we have unique clustered or non unique clustered index.
As already written earlier here, a Non clustered index will store clustered index key in its index.However, there is a small change in Non clustered index when the clustered index is defined as Non unique.When one searches using the Non clustered index , the clustered index key helps in reaching the actual row in the table. But, when the clustered index is not unique SQL Server adds a additional Unique identifier column along with the clustered index key on the non clustered index. We will see the same using DBCC IND and DBCC PAGE commands.
Table structure is provided below. Students table has 2 columns namely 'student_name','sid'.'sid' has a UNIQUE clustered index. student_name has a non clustered index.
CREATE TABLE [dbo].[students]
(
[student_name] [VARCHAR](50) NULL,
[sid] [INT] NULL
)
ON [PRIMARY]
CREATE UNIQUE CLUSTERED INDEX [CIX_students_id]
ON [dbo].[Students] ( [sid] ASC )
CREATE NONCLUSTERED INDEX [IX_students_name]
ON [dbo].[Students] ( [student_name] ASC )
I have loaded about 100,001 rows on the table. Let us see the structure on Non clustered index [IX_students_name] using DBCC IND/PAGE command.
Following steps are involved in reading the structure of the index.
1) Finding the root page of the index.
Execute the following command.
DBCC ind ( dbadb, students, 2)
GO
The third parameter is the ID of Non Clustered index [IX_students_name] which is obtained from sysindexes table.So we see only the pages of [IX_students_name] in our result set.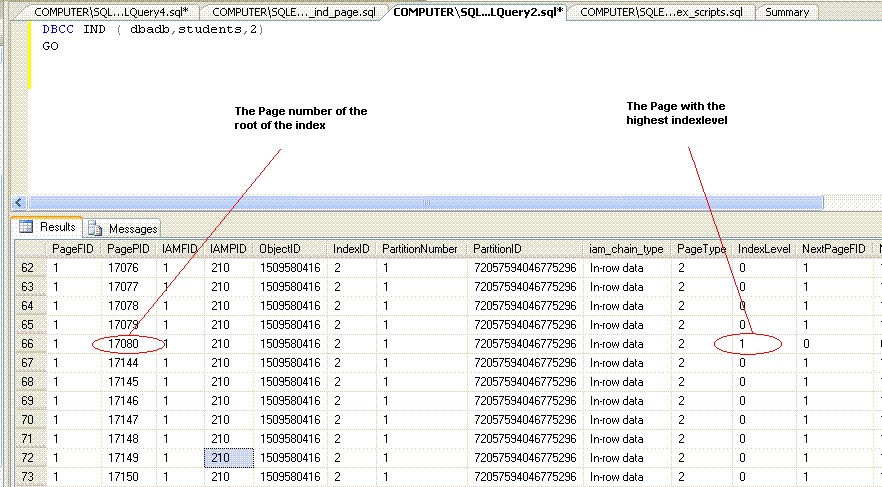
The command will show all the pages in the index. To identify the root of the index , identify the row with the highest Indexlevel. Indexlevel 0 refers to leaf pages. In Students table, the highest Indexlevel is noted as 1( which means there are only two levels on the index ie root and leaves ) and the page number is 17080.
2) Checking the contents of the root page
For checking contents of the root page execute the following command.
DBCC traceon(3604)
DBCC page(dbadb, 1, 17080, 3)
GO 
You would see the non clustered key and clustered index key ( sid ) column on the root page of [IX_students_name].But there wont be any Unique Identifier as the Clustered index is unique.
Non clustered index structure with a non unique clustered index:
Now let us check the structure of the Non clustered index when we have Non Unique clustered index.For that let us alter our clustered index to non unique cluster using the following command.I have just removed the UNIQUE keyword from the earlier script and recreated the clustered index using DROP_EXISTING = ON option.
CREATE CLUSTERED INDEX [CIX_students_id]
ON [dbo].[Students] ( [sid] ASC )
WITH ( drop_existing = ON) ON [PRIMARY]
After executing the above command, the clustered index is non unique.
Now let us again analyze the structure of Non clustered index.
1) Root of the index
DBCC ind ( dbadb, students, 2)
GO 
Root page number is noted as 15992
2) Contents of the root page
DBCC traceon(3604)
DBCC page(dbadb, 1, 15992, 3)
GO 
Picture of index page with Uniquifier
You would notice that a new column called 'Uniquifier' is added to the non clustered index's leaf page as the clustered index is not unique anymore. Uniquifier has NULL values as there are no duplicate rows in the table.
Let us introduce a duplicate value in the table using the following script.
SELECT *
FROM students
WHERE sid = 100000
GO
/* just to confirm that i have only one row. */
INSERT INTO students
SELECT *
FROM students
WHERE sid = 100000
/* Manually inserting a duplicate */
SELECT *
FROM students
WHERE sid = 100000
GO
/* Verifying that we have a duplicate */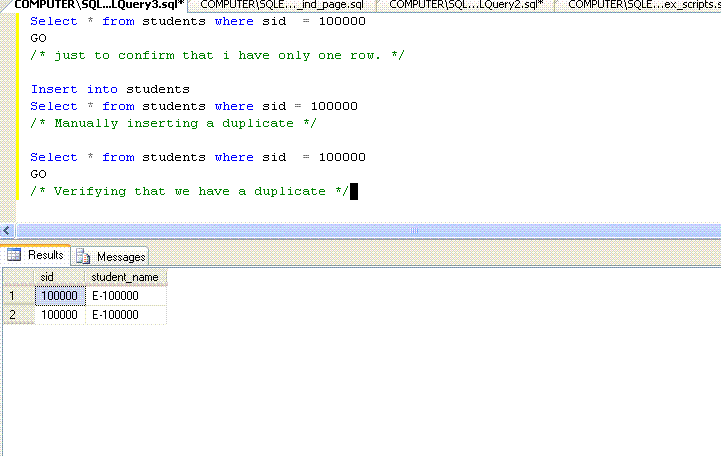
Note that the row has a value E-100000 on student_name column
Locating a value with in the index using DBCC IND/ DBCC PAGE:
To see how uniquifier is used in Non clustered index ,we need to find the duplicate row on the Non Clustered index with the value 'E-100000'. To do the same let us follow the following steps.
1) Finding the root page:
We already know that root page id of [IX_students_name] is 15992
2) Identify the page in which E-100000 is residing
Fire the same DBCC page command used earlier
DBCC traceon(3604)
DBCC page(dbadb, 1, 15992, 3)
GO
The resultset of DBCC PAGE is quite similar to a telephone directory index page where key column(s) ( student_name ) is the name of the person we are searching for and ChildPageid column is the Pagenumber in the directory.
For example,observe the Picture of index page with Uniqufier posted above.The value A-19032 on the student_name column ( 2nd row ) indicates that page number 15929 ( child page id ) contains rows starting from A-19032 and just before 'A-28080'. So to find E_10000 we should scroll to the row that exceeds (alphabetically) E-10000 by just and then goto the previous row and pick up the corresponding childpageid.
Observe the first row that alphabetically exceeds E-100000.
Refer to the row before that which is likely to contain E-100000.ChildPageID gives the page number of the page linked to row. The Childpageid on the immediate previous row exceeding E-100000 is 8605. So Page number 8605 should contain E-100000.So, execute the following command.
DBCC page(dbadb, 1, 8605, 3)
GO 
Notice two rows with 'E-100000' which reflect the duplicate row we inserted earlier.
Note the uniquiefier column for rows containing E-100000. They have values of 0,1 which will be used to identify the correct row in the clustered index.
So, the conclusion of this long post is if you have a Non unique clustered index,
then additional Uniquifier column will be added in the Non clustered index to locate the correct row.
Monday, August 2, 2010
DBCC IND, DBCC PAGE - Intro
DBCC IND
DBCC IND command provides the list of pages used by the table or index. The command provides the page numbers used by the table along with previous page number,next page number. The command takes three parameters.
Syntax is provided below.
DBCC ind ( <database_name>, <table_name>, non clustered index_id*)
The third parameter can either be a Non Clustered index id ( provided by sys.indexes ) or 1,0,-1,-2. -1 provides complete information about all type of pages( in row data,row over flow data,IAM,all indexes ) associated with the table. The list of columns returned are provided below.
IndexID: Provides id of the index. 0 - for heap, 1 - clustered index.,Non
clustered ids > 2 .
PagePID : Page number
IAMFID : Fileid of the file containing the page ( refer sysfiles )
ObjectID : Objectid of the table used.
Iam_chain_type: Type of data stored ( in row data,row overflow etc )
PageType : 1 refers to Data page, 2 -> Index page,3 and 4 -> text pages
Indexlevel: 0 - refers to leaf. Highest value refers to root of an index.
NextPagePID,PrevPagePID : refers to next and previous page numbers.
Example:
The command provides the pages used by table named Bigtable in database dbadb.
DBCC ind(dbadb, bigtable, -1)

DBCC PAGE:
Next undocumented command we would be seeing is DBCC PAGE:
DBCC PAGE takes the page number as the input parameter and displays the content of the page.Its almost like opening database page with your hands and viewing the contents of the page.
Syntax:
DBCC page(<database_name>, <fileid>, <pagenumber>, <viewing_type>)
DBCC PAGE takes 4 parameters. They are database_name, fileid, pagenumber, viewing_type.Viewing_type parameter when passed a value 3 and displays the results in tabular format.If you are viewing a data page then the results are always in text format. For Index pages, when we pass the value 3 as parameter we get the results in a tabular format.DBCC PAGE command requires the trace flag 3604 to be turned on before its execution.
A sample call is when a Index page is viewed is provided below:
Note that the page number picked (9069) is a page from clustered index of the table
'Bigtable'. 'Bigtable' has a clustered index on a column named 'id' .
DBCC traceon(3604)
GO
DBCC page(dbadb, 1, 8176, 3)
GO

Useful columns returned are provided below:
Level : Index level
id(Key) : Actual column value on the index. The indexed column name suffixed with '(key)' becomes a part of a result set. If your index has 4 columns then 4 columns with the suffix '(key)' will be a part of your result set. In the above example the data/values on column 'id' present in the page 8176 are displayed.
ChildPageid: Pageid of the child page.
A sample call when a data page number is passed is shown below:
DBCC traceon(3604)
GO
DBCC page(dbadb, 1, 9069, 3)
GO
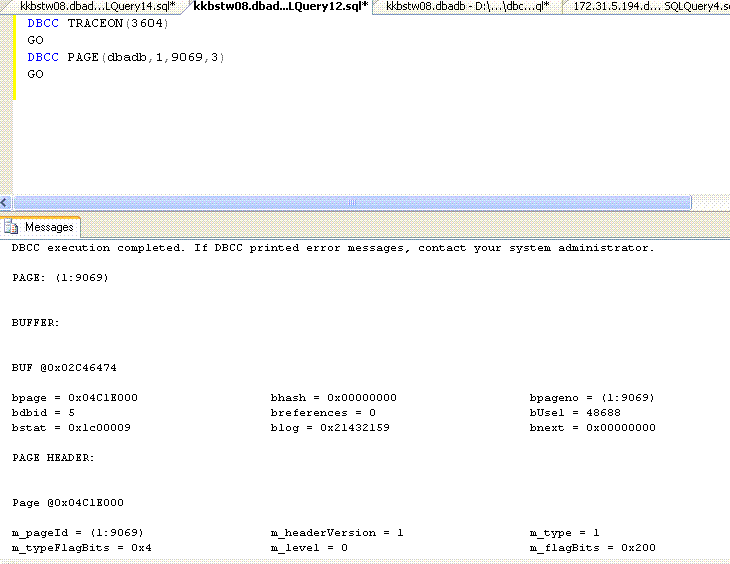
Bit cryptic to read the text format results. But anyways we will using it less compared to index page results.
What we intend to do with these two commands ?
These two commands help us understand index structures, they way pages have been allocated and linked in a much better way. DBCC IND and PAGE are the two commands with which we can really get our hands dirty while trying to understand index structures. In the next couple of posts, I will analyze index structures using these commands and provide some interesting inferences on how index structures are arranged internally.
References : As usual Kalen Deanley - SQL Server Internals :)