Continuing from the last post, let us analyze the structure of a non clustered index using DBCC IND/PAGE commands, when we have a clustered index on the table. To be specific, we will see the difference in structure of a Non Clustered index when we have unique clustered or non unique clustered index.
As already written earlier here, a Non clustered index will store clustered index key in its index.However, there is a small change in Non clustered index when the clustered index is defined as Non unique.When one searches using the Non clustered index , the clustered index key helps in reaching the actual row in the table. But, when the clustered index is not unique SQL Server adds a additional Unique identifier column along with the clustered index key on the non clustered index. We will see the same using DBCC IND and DBCC PAGE commands.
Table structure is provided below. Students table has 2 columns namely 'student_name','sid'.'sid' has a UNIQUE clustered index. student_name has a non clustered index.
CREATE TABLE [dbo].[students]
(
[student_name] [VARCHAR](50) NULL,
[sid] [INT] NULL
)
ON [PRIMARY]
CREATE UNIQUE CLUSTERED INDEX [CIX_students_id]
ON [dbo].[Students] ( [sid] ASC )
CREATE NONCLUSTERED INDEX [IX_students_name]
ON [dbo].[Students] ( [student_name] ASC )
I have loaded about 100,001 rows on the table. Let us see the structure on Non clustered index [IX_students_name] using DBCC IND/PAGE command.
Following steps are involved in reading the structure of the index.
1) Finding the root page of the index.
Execute the following command.
DBCC ind ( dbadb, students, 2)
GO
The third parameter is the ID of Non Clustered index [IX_students_name] which is obtained from sysindexes table.So we see only the pages of [IX_students_name] in our result set.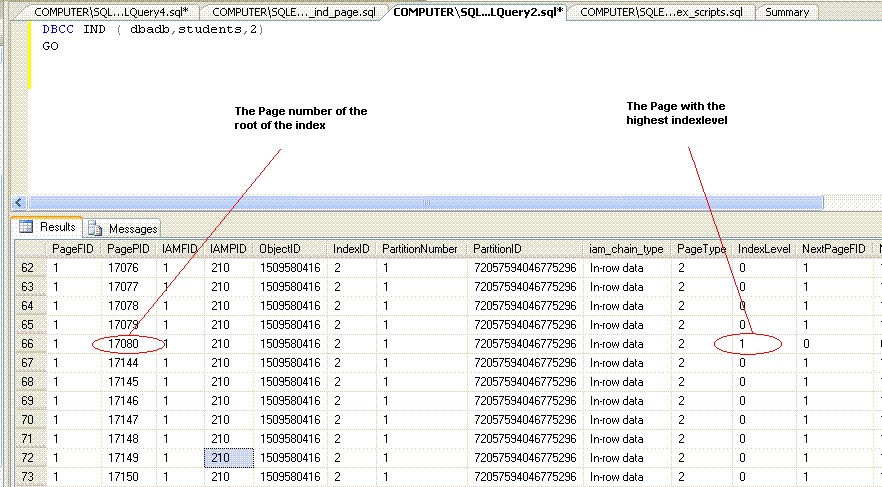
The command will show all the pages in the index. To identify the root of the index , identify the row with the highest Indexlevel. Indexlevel 0 refers to leaf pages. In Students table, the highest Indexlevel is noted as 1( which means there are only two levels on the index ie root and leaves ) and the page number is 17080.
2) Checking the contents of the root page
For checking contents of the root page execute the following command.
DBCC traceon(3604)
DBCC page(dbadb, 1, 17080, 3)
GO 
You would see the non clustered key and clustered index key ( sid ) column on the root page of [IX_students_name].But there wont be any Unique Identifier as the Clustered index is unique.
Non clustered index structure with a non unique clustered index:
Now let us check the structure of the Non clustered index when we have Non Unique clustered index.For that let us alter our clustered index to non unique cluster using the following command.I have just removed the UNIQUE keyword from the earlier script and recreated the clustered index using DROP_EXISTING = ON option.
CREATE CLUSTERED INDEX [CIX_students_id]
ON [dbo].[Students] ( [sid] ASC )
WITH ( drop_existing = ON) ON [PRIMARY]
After executing the above command, the clustered index is non unique.
Now let us again analyze the structure of Non clustered index.
1) Root of the index
DBCC ind ( dbadb, students, 2)
GO 
Root page number is noted as 15992
2) Contents of the root page
DBCC traceon(3604)
DBCC page(dbadb, 1, 15992, 3)
GO 
Picture of index page with Uniquifier
You would notice that a new column called 'Uniquifier' is added to the non clustered index's leaf page as the clustered index is not unique anymore. Uniquifier has NULL values as there are no duplicate rows in the table.
Let us introduce a duplicate value in the table using the following script.
SELECT *
FROM students
WHERE sid = 100000
GO
/* just to confirm that i have only one row. */
INSERT INTO students
SELECT *
FROM students
WHERE sid = 100000
/* Manually inserting a duplicate */
SELECT *
FROM students
WHERE sid = 100000
GO
/* Verifying that we have a duplicate */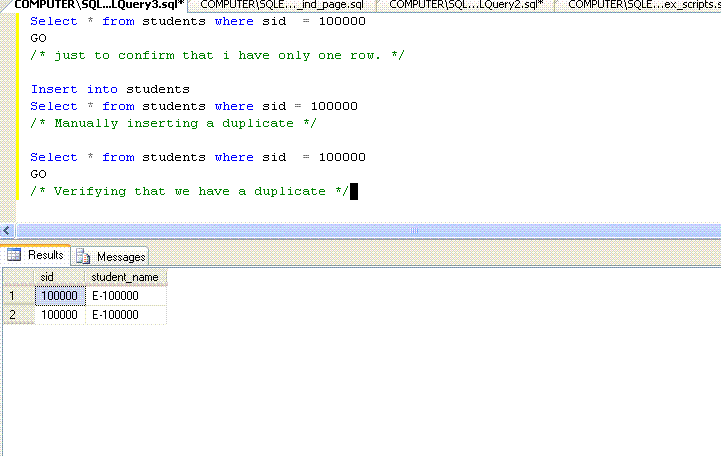
Note that the row has a value E-100000 on student_name column
Locating a value with in the index using DBCC IND/ DBCC PAGE:
To see how uniquifier is used in Non clustered index ,we need to find the duplicate row on the Non Clustered index with the value 'E-100000'. To do the same let us follow the following steps.
1) Finding the root page:
We already know that root page id of [IX_students_name] is 15992
2) Identify the page in which E-100000 is residing
Fire the same DBCC page command used earlier
DBCC traceon(3604)
DBCC page(dbadb, 1, 15992, 3)
GO
The resultset of DBCC PAGE is quite similar to a telephone directory index page where key column(s) ( student_name ) is the name of the person we are searching for and ChildPageid column is the Pagenumber in the directory.
For example,observe the Picture of index page with Uniqufier posted above.The value A-19032 on the student_name column ( 2nd row ) indicates that page number 15929 ( child page id ) contains rows starting from A-19032 and just before 'A-28080'. So to find E_10000 we should scroll to the row that exceeds (alphabetically) E-10000 by just and then goto the previous row and pick up the corresponding childpageid.
Observe the first row that alphabetically exceeds E-100000.
Refer to the row before that which is likely to contain E-100000.ChildPageID gives the page number of the page linked to row. The Childpageid on the immediate previous row exceeding E-100000 is 8605. So Page number 8605 should contain E-100000.So, execute the following command.
DBCC page(dbadb, 1, 8605, 3)
GO 
Notice two rows with 'E-100000' which reflect the duplicate row we inserted earlier.
Note the uniquiefier column for rows containing E-100000. They have values of 0,1 which will be used to identify the correct row in the clustered index.
So, the conclusion of this long post is if you have a Non unique clustered index,
then additional Uniquifier column will be added in the Non clustered index to locate the correct row.
Monday, August 9, 2010
DBCC IND/ PAGE - Non Clustered Index structure on a table with Unique/Non unique Clustered index
Subscribe to:
Post Comments (Atom)
2 comments:
Great post.
thank you
First time reading this, thanks for sharing
Post a Comment