Quick summary of the post:
A restoration of a full database backup retains the log file size before restoration.
Now for the details :
Consider a large database that you want to move from one server to another. Assume that the log file of the source database is huge. For taking a backup, the size of the log file doesn't matter as a backup operation always backs up only the used pages of database.After restoration, the restored database's log file size is same as the original database, even though the backup file used for restoration
is much smaller. If one has a space constraint in the destination server, then its better to shrink the log before taking the backup of the original
database.
Let us take the sample database dbadb . The database size is 107 MB with data file size being 16 MB and log file size being 91 MB. A full backup file size is only 3.2 MB
Database size 
Full Backup size 
A restore of the backup will create a database again at the original size of 107 MB with data and log file sizes being 16 MB and 91 MB respectively.
Restore of Database 
Database size of restored database 
So, if your destination server doesn't have enough space, then ensure your log file size is small before taking the full backup.
Tuesday, November 1, 2011
Log file size after backup and restore
Tuesday, October 4, 2011
Backup/Restore vs Detach & Attach
You want to move a database from one server to another. There are two options to do that.
1) Detach/Attach: To Detach the database from source server and copy the Data and log file ( MDF and LDF ) of the database and attach it in the destination server
2) Backup/Restore: Perform a SQL Backup of the database and move the
backup file to destination server and Restore the database in destination server.
A simple comparison of both the methods.
Detach/Attach | Backup and Restore |
Detach/Attach is a offline operation. Source database will be inactive when you perform detach and attach operation | Source database can be accessed as it is a online operation |
Detaching and Attaching the database happens instantly irrespective of the size of the database.Time taken in migrating the database is same as the time taken for copying the data and log files from one server to another | Backing up a database can take considerabale amount of time ranging from few minutes to many hours depending upon the database. Restore of a database on a average takes about 3 times of backup time. So, total time taken in migrating the database would be backup time + restore time + time taken to move the backup file from one server to another |
Sometimes, if the Log file size is huge then one needs to copy large amount of data over the network | Backup file contains only used data pages in data file and hence the size of the backup file would not include the size of data log file |
Sometimes, if the Log file size is huge then one needs to copy large amount of data over the network | Backup file contains only used data pages in data file and hence the size of the backup file would not include the size of data log file |
If the data file is fragmented/ If the Data file has lots of free space with in the file ( allocated but unused ), then copying the data file would mean carrying additional bytes of data though the they are unused. | Backup copies only used data pages of the data file. So, the size of the backup is always close to the size of the size used with in the data file. |
Detach / Attach is not recorded in any table in msdb database. so one has no record of who detached/atatched who or when was it done, what were the files detached, what size or where the files are stored etc. | Backup and restore operation details are always stored in msdb database tables with information like size,date,location,type of backup / restore. |
Advanced options like mirrored backup/ partial backup/ compressed backup/ backup to tape/ point in time recovery are not available | All advanced options are available |
Detach and attach method is useful when one wants move the database fast, without caring much about the availaiblity of source server.Backup and Restore is certainly a much graceful way to do the same.
Thursday, August 25, 2011
Reading SQL Error log
SQL Error log can be read from SQL Server's management studio. However, Management studio is too slow and definitely not the greatest way of taking a quick look at SQL Error log. Sp_readerrorlog is definitely a much better command which can help us read a error log must faster way. Also , the script below Dumps the read error log into a temporary table. Once dumped one can use different kinds of filters as per our needs.
The script below loads error log into a temporary table, filters for a particular date range, removes error log entries for backup, and searches only for genuine error on the error log.
CREATE TABLE #error_log_dt
(
logdate DATETIME,
processinfo VARCHAR(30),
text_data VARCHAR(MAX)
)
INSERT INTO #error_log_dt
EXEC Sp_readerrorlog
SELECT *
FROM #error_log_dt
WHERE logdate BETWEEN '20110815' AND '20110821'
AND processinfo != 'backup'
AND text_data LIKE '%error%'
DROP TABLE #error_log_dt
Saturday, June 25, 2011
ALTER TABLE - Adding Column - Column Order Impact
Most of us would have altered a table structre by adding a column to the table. When an ALTER table script is used to add the column to the table, the column is placed on the last of the table. For inserting a column, in the middle of the table one needs to use the SQL Server Management Studio ( SSMS ).ie., Right click on the table and pick design table and then proceed to add a column. This post will deal with the significance of column order while adding a column to the table.
Consider the table 'sample'. The table contains about 800 rows with a size of 6 MB. Relatively small by a normal database standards.
Let us add column in the middle using SSMS as shown below. Once we click on save button to save the column addition, the operation completes immediateley.
Let me add a few more rows into the table. Now the table contains over 200K rows and the size of the table is 1.6 GB.
Now let me add a column to the middle of the table using SSMS as done proviously. Now the operation takes much much longer. Just in case if you face timeout error refer here.
Now the operation takes few hours to complete and the new column will be inserted between two columns as shown below.
Let us add one more column at the last of the table ( not in between the columns as doen previously). Refer to picture below.
ALTER TABLE sample ADD col3_int CHAR(5) 
Now the operation takes in 0 seconds to complete. The points to note are provided below.
* When we add a column to the middle of the table using SSMS, when the number of rows are higher, it consumes a longer execution time and resource.
However, when the number of rows are lesser it doesnt consume much of time and CPU/IO resource. This aspect is to be handled carefully where a DBA can fall for the trap if overlooked.
Assume, DBA is planning to perform a small column addition on the production server. DBA has already tested in staging and it was over in few seconds. DBA assumes that the operation is going to take a few seconds in production and plans accordingly. If the number of rows are higher in production, the DBA can be taken for ride and it can be different ball game all together.
So lesson to be learnt is Dont underestimate any table modification prepations and make sure to check size/# of rows on production before deployment.
* When the column was added to the end of the table ( without caring about position of the column ) using T-SQL script ( ALTER TABLE coomand ),it completed immediately without consuming much of time and resource, though the number of rows were very high.
Lesson learnt is insertion of a column to the middle ( or rather between two other columns ) of the table should not be done, unless there is a strong reason to do so. If there is no strong reason, then always add the column to the end of the table using ALTER TABLE script as they take much much lesser time to execute.
* Use scripts instead of SSMS GUI especially while performing table strucutre modifications or DDL operations.
We will take a much closer look in the next post exploring why such a behavior is observed.
Friday, June 17, 2011
Altering Table structure - SSMS - Timeout Expired
Altering a table using SQL Server Management Studio ( SSMS ) can be done by right clicking on the table and by picking the design table as shown below.
While adding a column, especially for a huge table, then management studio prompts saying changing the data can consume lot of resources and time as shown below.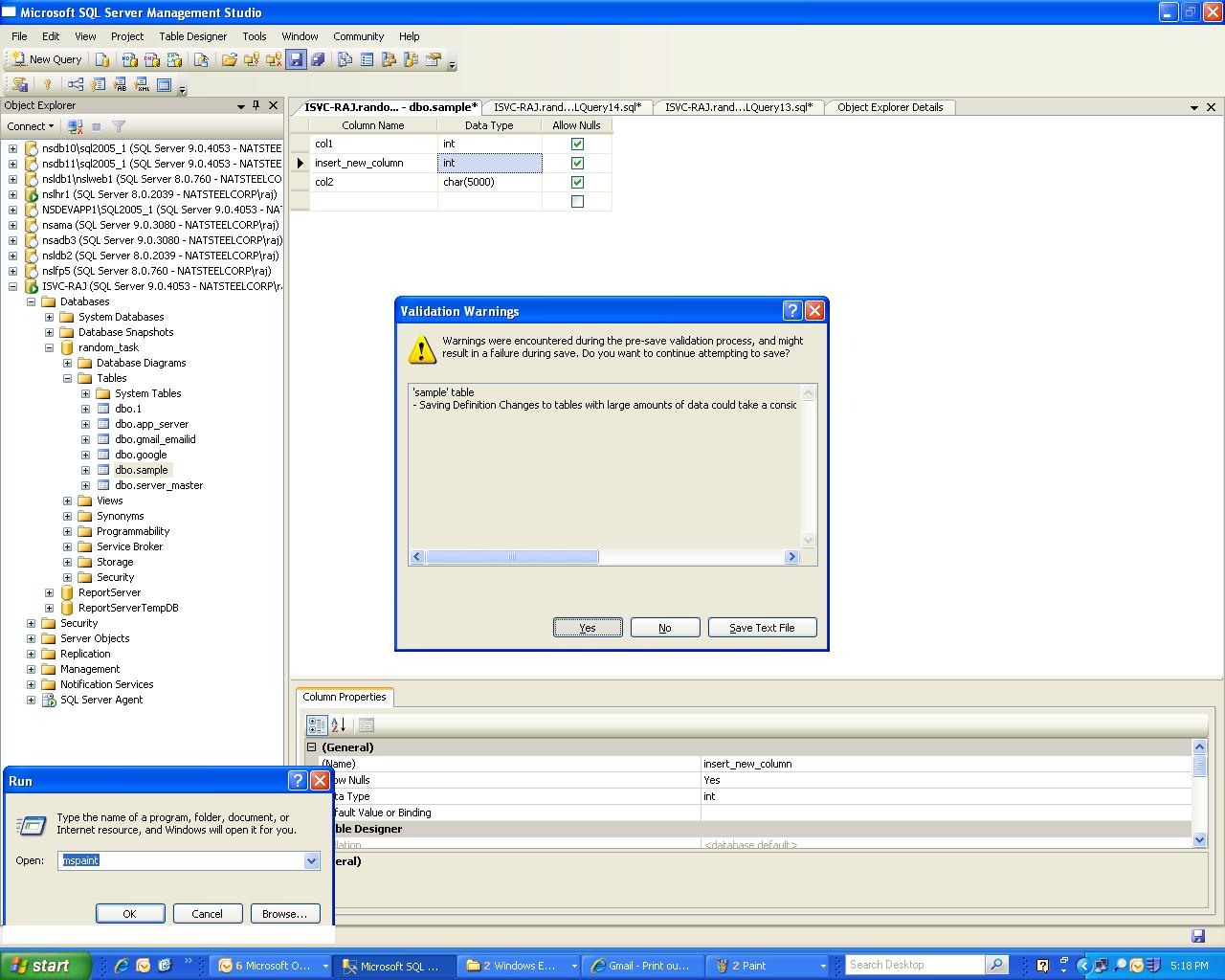
After clicking 'yes', if the alter table takes longer than 30 secs then the alter table fails with the error message 'Time out expired' as shown below.
The error can be avoided by changing the default setting in SSMS as shown below. Goto Tools->Options->Tables and Database Designer and set the option Transaction time out after to 1800 seconds from default 30 seconds . The default setting is shown below.
Sunday, June 12, 2011
Database Owner - Error Message
Sometimes, a simple task that as a DBA you do day in and day out,
can throw wierd errors.
You right click on a database and click on Properties to check
the Database Size/ Database path. Suddenly, a error message as shown
below is thrown at you.
The error message says the problem is with the database owner. When the database owner is removed ( perhaps the login was dropped ) , such a error message is thrown.The problem can be rectified by using the command
EXEC MASTER.dbo.Sp_changedbowner 'sa'
GO
The command sets database owner as dbo and solves the problem. Now we can comfortably view database property from SSMS as usual.
Please note that sp_changedbowner command is marked for depcreation and users are recommended to use ALTER AUTHORIZATRION command.syntax is provided below.
ALTER AUTHORIZATION ON DATABASE::dbname TO principal;
For more details on AUTHORIZATION refer here
Saturday, June 11, 2011
I am back
I am back again!!!. It has been ages since I posted.An important event in my life kept me away from blogging. Now I am happily married to Sharadha. :) Till date, I havent posted a photograph of mine in this blog. Today is certainly a good day to that.
So, from now on the blog will be active as it was before and special thanks to all the readers for visiting even when it was not frequently updated.
Tuesday, January 4, 2011
Finding last database growth date and time
A file growth operation on a database server is a extremely expensive operation. Many Performance problems correlate to a Data or log file growth event on the database. As a result its extremley important for a DBA, to have a way to check the time of Data or Log file growth occured earlier. A good way of finding it will be thro SQL default trace. Refer to the following query
DECLARE @path NVARCHAR(1000)
SELECT @path = Substring(PATH, 1, Len(PATH) - Charindex('\', Reverse(PATH))) +
'\log.trc'
FROM sys.traces
WHERE id = 1
SELECT databasename,
e.name AS eventname,
cat.name AS [CategoryName],
starttime,
e.category_id,
loginname,
loginsid,
spid,
hostname,
applicationname,
servername,
textdata,
objectname,
eventclass,
eventsubclass
FROM ::fn_trace_gettable(@path, 0)
INNER JOIN sys.trace_events e
ON eventclass = trace_event_id
INNER JOIN sys.trace_categories AS cat
ON e.category_id = cat.category_id
WHERE e.name IN( 'Data File Auto Grow', 'Log File Auto Grow' )
ORDER BY starttime DESC 
The script provided above will list the databases that grew recently along with their time of growth. The script pulls these details from SQL Server''s default trace. Default trace is a light weight trace running at the background by default capturing many important events. Few of them are listed below.
Data File Auto Grow
Data File Auto Shrink
Database Mirroring State Change
ErrorLog
Full text crawl related events
Hash Warning
Log File Auto Grow
Log File Auto Shrink
Missing Column Statistics
Missing Join Predicate
Object:Altered
Object:Created
Object:Deleted
Plan Guide Unsuccessful
Server Memory Change
Sort Warnings
SQL default trace can write upto 5 files with each file with a maximum size 0f 20 MB.
So maximum log of 100 MB will be generated. So, the amount of time SQL Trace retains the log details depends on the amount of activity on the server.One can change the same script to view other events and get other useful info like 'who altered that object?' , 'Who granted the rights to a particular table' and so on.
For more details on default trace refer here and here and here