Scalar functions as discussed in the last post can be a performance bottleneck.Another place where Scalar functions ( both user defined and system ) can become a performance bottleneck is when used on a where clause of the query. Scalar functions when used on a where clause of a query can make the optimizer pick a table scan, even if the index is present, making the index useless.
/****** Object: Index [ncix_Supplier_product_customer_trans_date] ******/
CREATE NONCLUSTERED INDEX [ncix_Supplier_product_customer_trans_date]
ON [dbo].[Supplier_Product_Customer] ( [trans_date] ASC )
ON [PRIMARY]
A non clustered index on trans_date column of supplier_product_customer table has been created.When one needs to find the list of transactions for a particular day ( cutting the time part of the , the most common method of writing the query would be
SELECT *
FROM [Supplier_Product_customer]
WHERE Datediff(dd, [trans_date], '11/19/2009') = 0
But,the problem with such a query is that it takes table scan instead of using the Non clustered index created on trans_date. The reason is that scalar function datediff used on trans_date column stops the query analyzer from using the index.
A better way of writing it would be
SELECT *
FROM supplier_product_customer
WHERE trans_date >= '20091119'
AND trans_date < '20091120' 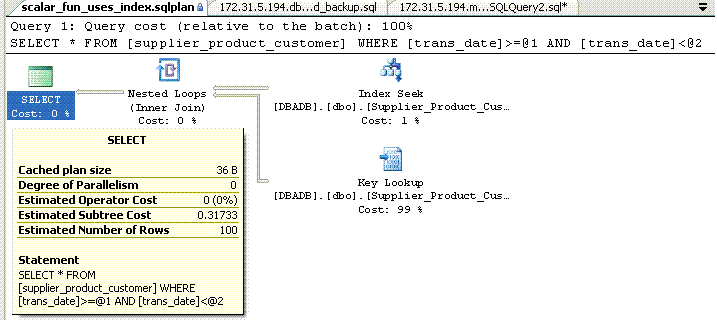
The picture above shows a non clustered index seek instead of table scan. There are few other common scenarios where functions can be avoided. Let me briefly list them here
* Left() string fuction can be effectively replaced by like
'str%'
* Usage of upper/lower string functions can be avoided
when the database has a case insensitive collation.
* isnull(col1,'xyz') = 'xyz' can be replaced by col1 = 'xyz'
or col1 is null
Note that OR conditions do use indexes and but at times they don't.
Please check before use.
* Getting data older than 60/n days query.
Standard way of doing it would be
Where datediff(dd, trans_date, getdate()) > 60
Replaced by
Where trans_date < CONVERT(VARCHAR, getdate()-60, 112)
To Conclude, one should try the best to avoid having scalar functions in where clauses.
Sunday, June 6, 2010
Scalar functions - on where clause
Subscribe to:
Post Comments (Atom)
4 comments:
Thanks for the post!
Could where clauses possibly return the wrong information?
select m.id
from table m
where m.course in
('05','06','07','08','09','10')
and m.type = 'AuditOnly'
and m.gender = 'M'
returns zero, but:
select m.id
from table m
where m.course in
('05','06','07','08','09','10')
intersect
select m.id
from table m
where m.type = 'AuditOnly'
intersect
select m.id
from table m
where m.gender = 'M'
returns a few hundred. Why the difference?
Interesting comment Anony. Thanks. The difference is because the way in which intersect operates. There is no problem with where clause.
Interesct executes each part of the query individually and then prints the results like a set interesection ie prints the rows that have the same value on the select column.But interesect doesnt check whether all the 3 conditions are satisfied on the same row. Meaning interesect doesnt check whether the your m.id at all the three queries comes from the same row. As where clause applies all the conditions at one go it checks whether all the conditions are satisfied for the same row. Grab a look at the sample query posted by me below..
create table #temp(id int, c1 varchar(5),c2 varchar(5))
Insert into #temp Select 1,'A','Z'
Insert into #temp Select 1,'B','Y'
Insert into #temp Select 1,'C','X'
Select * from #temp
where id = 1 and c1 = 'B' and c2 = 'X'
Select id
from #temp where id = 1
intersect
Select id
from #temp where c1 = 'B'
intersect
Select id
from #temp where c2 = 'X'
Please post if still not clear or if you have any more doubts.
Thanks! However, what if the ID is unique?
If the ID is unique, then the results for the case explained should be same.
Post a Comment